1 问题描述
最近在跑一些模型时需要用到Docker,但出现了无法使用宿主机GPU的情况,在此记录一下解决过程。
首先介绍一下Docker吧,照例,Wiki上的介绍:
Docker容器与虚拟机类似,但二者在原理上不同。容器是将操作系统层虚拟化,虚拟机则是虚拟化硬件,因此容器更具有便携性、更能高效地利用服务器。 容器更多的用于表示软件的一个标准化单元。由于容器的标准化,因此它可以无视基础设施(Infrastructure)的差异,部署到任何一个地方。
简单来说,Docker可以理解为一个实现原理不同的虚拟机,可以将程序运行需要的环境进行一个整体的打包,然后部署到任何支持Docker的平台上,方便复现与调试。
2 安装与调试
2.1 安装 NVIDIA Container Toolkit
首先,要想在Docker内部使用宿主机的GPU(默认为Nvidia)必须首先安装NVIDIA Container Toolkit,简单记录一下安装步骤(Ubuntu系统下):
添加源:
1
2
3
4curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list更新包列表:
1
sudo apt-get update
安装NVIDIA Container Toolkit包:
1
sudo apt-get install -y nvidia-container-toolkit
使用NVIDIA Container Toolkit修改Docker配置文件(
/etc/docker/daemon.json),将nvidia-container-runtime添加至Docker可用运行时列表,从而使得Docker环境可使用宿主的GPU:1
sudo nvidia-ctk runtime configure --runtime=docker
重启Docker:
1
sudo systemctl restart docker
完成上述步骤之后可以查看/etc/docker/daemon.json,正常应该如下所示:
1 | { |
2.2 测试 Docker
完成上述操作后,可以测试一下Docker环境下是否可以正常使用宿主机的GPU,通过以下命令进行测试:
1 | sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi |
该命令是为ubuntu镜像(该镜像模拟一个Ubuntu环境)创建一个临时容器,--gpus all参数表示在Docker环境中使用宿主机的GPU,并在该容器内运行nvidia-smi,正常情况下应该会出现如下界面:
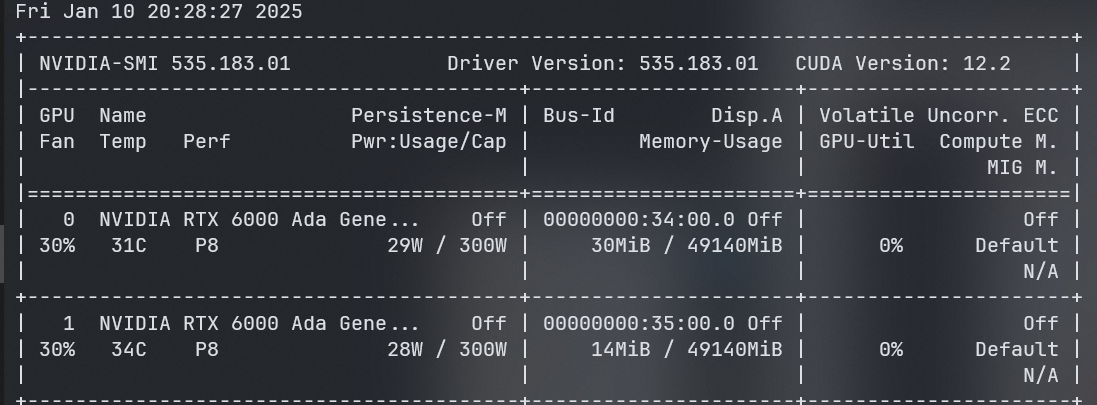
如果出现上图证明成功实现了Docker环境下宿主机GPU的调用,然而,我在测试时出现了报错:
1 | Failed to initialize NVML: Unknown Error |
2.3 问题解决
在网上搜索之后,在该文章中找到了解决方案。修改以下文件:
1 | sudo vim /etc/nvidia-container-runtime/config.toml |
将no-cgroups设置为false:
1 | no-cgroups = false |
保存该文件,然后重启docker、进行测试:
1 | sudo systemctl restart docker |
然后就可以正常出现显卡信息,表明Docker环境可以正常调用宿主机的显卡了。