Runz, Martin, and Lourdes Agapito. “Co-Fusion: Real-Time Segmentation, Tracking and Fusion of Multiple Objects.” In 2017 IEEE International Conference on Robotics and Automation (ICRA), 4471–78. Singapore, Singapore: IEEE, 2017. https://doi.org/10.1109/ICRA.2017.7989518.
3 Overview of our Method
Co-Fusion 是一个可以实时处理每一帧输入图片的RGB-D SLAM 系统,本系统为场景中每一个分割的物体存储模型,而且可以独立跟踪它们的运动,每个模型是由一组3D 点构成的。本系统维护两组物体模型:当前在视野中可见的active 模型,以及曾经观测到的模型,但是目前不在视野中,记为inactive 模型。本系统的框架如Fig. 2所示,在初始化阶段,场景只包含一个active 模型——背景,初始化完成后,按照Fig .2的流程处理每一帧图片。

tracking 与 fusion 步骤是在GPU 上完成的,而segmentation 步骤是在CPU 上完成的。
3.1 Tracking
在当前帧中跟踪每一个active 模型的6DOF 位姿,通过最小化每个模型独立的目标方程来实现,该目标方程包含:
- 几何误差:基于稠密的iterative closest point (ICP) 对齐;
- 光度误差:基于当前帧和存储的3D 模型之间的颜色差异。
3.2 Segmentation
该阶段将当前帧中的每一个像素与某个active 模型/物体联系起来,有两种手段来实现该过程:motion 以及 semantic labels。
3.2.1 Motion segmentation
将运动分割构建为一个使用全连接的Conditional Random Field (CRF) 解决的分类问题,可在CPU 上实时处理。当将一个像素与一个运动模型联系起来时,unary potentials 编码一个几何 ICP 损失函数。
3.2.2 Multi-class image segmentation
利用基于深度学习的方法实现像素级的语义分割,作为动作分割的备选方案。
3.3 Fusion
本系统使用surfel-based 融合方法,利用新估计的6DOF 位姿将属于某个模型的点更新至其active 模型。其中,每个模型是由一个sufel 列表构成的,$\mathcal{M}_m^s \in (\mathbf{p}\in \mathbb{R}^3, \mathbf{n}\in \mathbb{R}^3, \mathbf{c}\in \mathbb{N}^3, w \in \mathbb{R}, r \in \mathbb{R}, \mathbf{t}\in \mathbb{R}^2)$ ,分别表示位置、法向量、颜色、权重、半径以及两个时间戳。
为了解决动态物体的跟踪问题,本系统使用 $\mathcal{T}_t = \{\mathbf{T}_{tm}()\}$ 来表示每个active 模型 $\mathcal{M}_m$ 在时间 t 相对于全局参考坐标系的位姿转换几何,即 $\mathbf{T}_{tm}$ 表示时间 t 时模型 $\mathcal{M}_m$ 的全局位姿。特别地,作者使用 $\mathbf{T}_{tb}$ 来表示背景模型的位姿转换。
5 Tracking Active Models
对于时间t 的图像帧中的每一个active 模型 $\mathcal{M}_m$ ,系统通过配准当前的深度图和前一帧的深度图(通过将存储的3D 模型利用t-1 的估计位姿进行投影而获取)来跟踪其全局位姿 $\mathbf{T}_{tm}$ ,对每一个active 模型进行独立优化和跟踪。
5.1 Energy
误差项包含ICP 几何误差和光度误差,其中光度误差是由预测的图片(将之前帧中存储的3D 模型投影而获取)与当前图片的颜色差异构成,
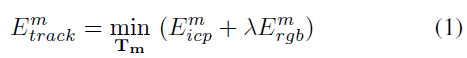
5.2 Geometry Term
ICP 几何误差定义为以下两者之间的误差:
- 当前帧深度图的逆向投影3D 点;
- 前一帧t-1 预测的深度图。
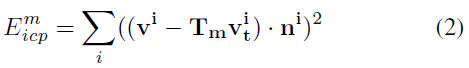
其中,$\mathbf{v}_t^i$ 是当前帧深度图 $\mathcal{D}_t$ 中第i 个点的反向映射3D 点;$\mathbf{v}^i, \mathbf{n}^i$ 分别是t-1 时刻预测的深度图中模型m 第i 个点的反向映射点以及其法向量;$\mathbf{T}_m$ 是将前一帧与当前帧的模型m 对齐的位姿转换。
5.3 Photometric Color Term
在给定(1)当前深度图、(2)每个active 模型的3D 几何估计,以及(3)将每个模型与前一帧对齐的位姿转换关系,即可将当前场景合成为一个与前一帧对齐的虚拟投影,进而,跟踪问题就变为了当前帧与合成的虚拟投影之间的光度配准问题:
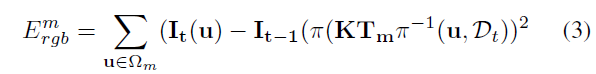
其中,$\mathbf{T}_m$ 是将前一帧与当前帧的模型m 对齐的位姿转换;$\mathbf{I}_{t-1}()$ 表示提供模型在前一帧上顶点的颜色参数。
为了鲁棒性和效率,本优化使用一个4层的空间金字塔来集成到一个由粗到细的方法中,并在GPU 中完成运算。
6 Motion Segmentation
在跟踪步骤之后,在t 时刻有 $M_t$ 个新的位姿转换 $\{\mathbf{T}_{tm}\}$ ,来描述每个active 模型相对于全局坐标系的绝对位姿;接下来作者将帧t 的运动分割问题构建为一个分类标记问题,而标签为 $M_t$ 个位姿转换 $\{\mathbf{T}_{tm}\}$ ,作者将 $M_t+1$ 种可能分配到每一个像素中,即 $\mathcal{l} \in \mathcal{L}_t = \{1, …, |M_t|+1\}$ ,除了 $M_t$ 个位姿转换 $\{\mathbf{T}_{tm}\}$外还包含一个外点标签 $\mathcal{l}_{|M_t|+1}$ 。
为了可以在CPU上实施完成分割步骤,系统首先将当前帧分割为SLIC 超像素,并在超像素级别上进行分类标记,超像素的位置、颜色与深度由从属的所有像素均值得到。代价函数如下所示:
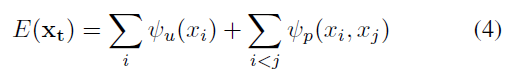
其中,i 和 j 图片中超像素的索引(从1到S)。
6.1 The Unary Potentials
对于 $\psi_u(x_i)$ 表示为超像素 $s_i$ 分配标签为 $x_i$ 的代价,对于运动分割模式,该代价为ICP 几何对齐损失函数(式 2)。
6.2 The Pairwise Potentials
对于 $\psi_p(x_i, x_j)$ 可表示为:
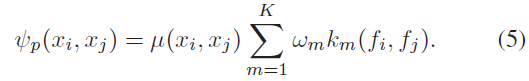
其中,$\mu(x_i, x_j)$ 惩罚临近像素标签不同的情况;$k_m(f_i, f_j)$ 测量像素外观之间的相似度,代表的含义是:两个超像素的特征向量之间的距离较小时应具有相同的标签,所谓的特征向量 $f_i$ 包含2D 位置、RGB 颜色以及深度值。
6.3 Post-processing
在分割之后,采用一系列后处理步骤来获取更为鲁棒的结果:
- 对具有相似位姿转换关系的模型进行融合操作;
- 抑制相同标签中除最大之外的所有区域来保证不连接区域的独立建模;
- 小于一定阈值的区域被舍弃。
6.4 Addition of New Models
一个区域内的外点数量若大于总像素数的3%,则判定该物体为一个新物体;若该新物体的部分几何结构已存在于地图中,会对重复的构建进行剔除。
如果一个物体消失在视野中,并在一定帧内不再出现,则将该模型添加进inactive 列表中。
7 Object Instance Segmentation
使用实例分割网络SharpMask 进行物体语义信息的获取。